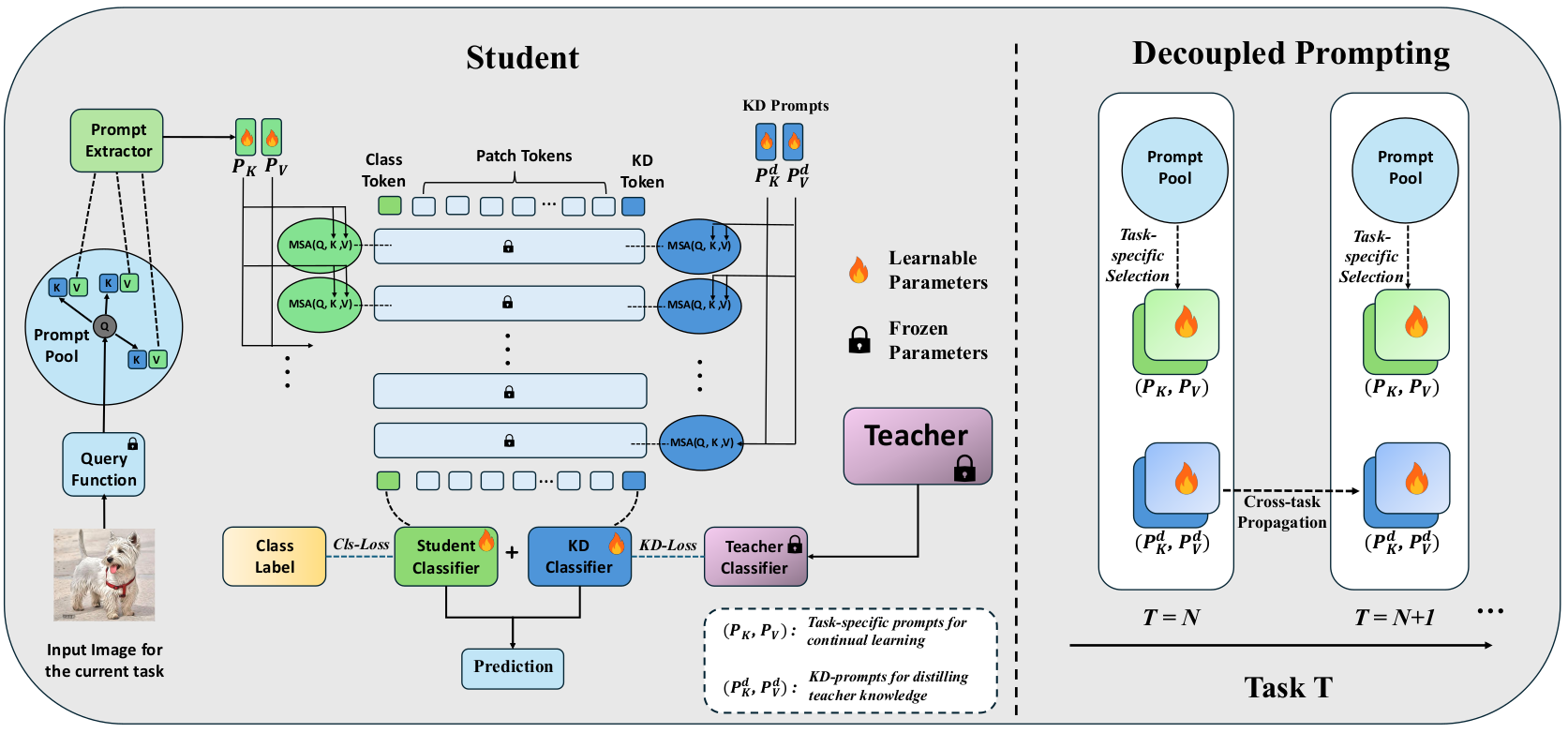
Prompt-based continual learning has shown strong performance in rehearsal-free class-incremental learning by adapting learnable prompts while freezing a pre-trained Vision Transformer (ViT) backbone. However, the effect of backbone scale remains underexplored. We observe that larger ViT backbones consistently yield better continual learning performance, which motivates us to study how to transfer such capability from a larger model to a smaller one. In this paper, we introduce Continual Distillation Learning (CDL), a new setting for knowledge distillation in rehearsal-free prompt-based continual learning. We show that conventional distillation methods provide only limited gains in CDL, mainly because task-specific prompts are forced to encode both continual adaptation and distillation knowledge, while lacking a persistent mechanism for cross-task knowledge transfer. To address this problem, we propose Decoupled Continual Distillation Learning (D-CDL), which introduces persistent Knowledge-Distillation prompts (KD-prompts) and a dedicated KD branch to explicitly decouple distillation from task adaptation. The proposed KD-prompts are propagated across tasks as a global carrier of teacher knowledge, while the original prompts remain responsible for continual learning. D-CDL is simple, general, and can be integrated into various prompt-based continual learning frameworks. Extensive experiments on Split CIFAR-100 and Split ImageNet-R across four representative continual learning methods show that D-CDL consistently outperforms existing distillation baselines and substantially improves student performance under different teacher-student settings.
we propose Decoupled Continual Distillation Learning (DCDL), which introduces persistent Knowledge-Distillation prompts (KD-prompts) and a dedicated KD branch to explicitly decouple distillation from task adaptation. The proposed KD-prompts are propagated across tasks as a global carrier of teacher knowledge, while the original prompts remain responsible for continual learning.
| # | Teacher | Student | Baseline | KD-Method | Task-Number | Accuarcy(%) | Forgetting(%) |
|---|
| # | Teacher | Student | Baseline | KD-Method | Task-Number | Accuarcy(%) | Forgetting(%) |
|---|
The code for CDL.
@misc{2024CDL,
title={Decoupled Prompting for Continual Distillation in Rehearsal-Free Class-Incremental Learning},
author={Qifan Zhang and Yunhui Guo and Yu Xiang},
year={2024},
eprint={2407.13911},
archivePrefix={arXiv},
primaryClass={cs.CV}
}Send any comments or questions to Qifan Zhang: qifan.zhang@utdallas.edu
This work was supported in part by the DARPA Perceptually-enabled Task Guidance (PTG) Program under contract number HR00112220005, the Sony Research Award Program, and the National Science Foundation (NSF) under Grant No. 2346528.


